Radio resource management, or RRM, is a key tool for large multi-site organizations to efficiently manage their RF spectrum.
Legacy controller-based implementations build their channel plan on how the APs hear each other. Usually late at night, and decisions on channel and power are then made and implemented.
The frustrations we hear from our large customers is that these systems focus solely on channel reuse, and don’t take into account changing conditions during the day, and then when it overreacts for no clear reason. Mist listened.
About two years ago, we completely redesigned RRM. Instead of just following how the APs hear each other vector, we wanted to take into account the user experience. So we already had the capacity, SLE, service level expectation, which is an actual measurement of every user minute, whether they had enough usable RF capacity available, taking into account client count, client usage, aka, bandwidth hogs, Wi-Fi and non-Wi-Fi interference.
So we implemented a reinforcement learning-based feedback model. We monitor the capacity SLE to see if a channel change and/or power change actually made things better for the users, or if it didn’t have any impact. We trained the system on these types of changes, and validate it with the capacity SLE to make sure there was a measurable improvement. This auto-tuning will continue on an ongoing basis.
Rather than setting 50 or more different thresholds. Based on raw metrics available from some vendors controller-based system, from experience, we know there is no perfect value that works across all environments.
Each environment is different, and probably not even consistent during the course of a single day. Picking static values and letting the system just run isn’t feasible and won’t scale. If the capacity SLE is showing 90%, then there isn’t much to gain by making changes.
The client usage classifier tracks excess bandwidth hogging by certain clients.
So if we see a two-sigma deviation for bandwidth usage among clients, then the higher usage clients would get flagged in the client usage classifier. If the bandwidth usage is pretty much ubiquitous across all clients, then the client count classifier is where that would be counted. These two events would not cause a channel change, but they would be visible in Marvis.
The capacity SLE is taking a hit, not based on client usage, but on Wi-Fi or non-Wi-Fi interference, then your end user experience is taking a hit. Our system is agile and dynamic. Rather than just setting min, max ranges, and being purely focused on channel reuse, we can let the system learn and adapt based on what the end users are experiencing. This is the underlying architecture for Mist AI-driven RRM.
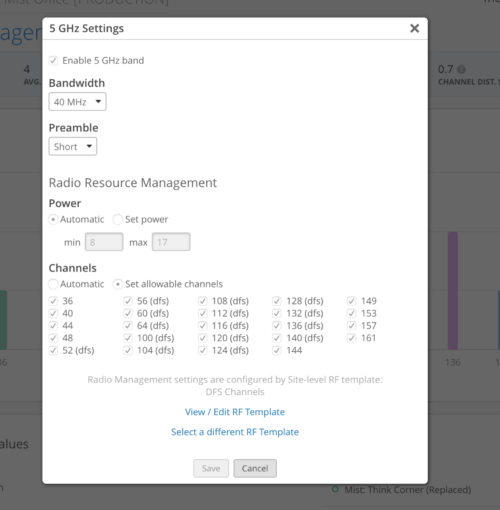
Let’s take a look at the available configuration options.
You can choose power range, your list of channels. These are the only things exposed, as everything else is auto baseline. So you don’t need to set a bunch of thresholds on each of your different sites, the system will self-learn per site based on the capacity SLE.
Mist has implemented RRM as a two-tier model. First, being global optimization, which runs once a day.
It collects data throughout the day on an ongoing basis, and creates a long-term trend baseline. And then every day, around 2:00 or 3:00 AM local time, it will make changes if those changes are warranted.
The second tier is event-driven RRM, or as we call it, internally local RRM. This is monitored by the capacity SLE, and will act immediately upon any deviation from baseline. So both of these are running in parallel. Conventional systems aren’t able to leverage the compute available in the cloud to constantly crunch the long-term trend data, and the ability to cross-pollinate information from all your different sites, different client types, and different RF environments.
An example would be buildings around an airport, where we have seen radar hits triggering DFS events. The cloud learns the geolocation and the specific frequencies of these events, and then cross-pollinates that learning to other sites that may also be close to that airport.
Existing systems have no memory and no concept of long-term trend data, they just make changes once a day. Here you can see events happening throughout the day. All of the events with the description are event-driven, and the scheduled are the optimizations that happen at night.
Some systems try to implement a pseudo local event type RRM, usually interference-based. But the problem we run into over time is drift. And as there’s no learning going on, eventually you’ll need to manually rebalance the system and clear the drift and start all over again. The reason for this, there is no memory of what happened, or the compute space to understand context and learn from it.
Mist RRM might also try to make a similar channel change, but first we’re going to go back and look at the last 30 days. And even though these three available channels look great now, we know one has had multiple issues in the past. So we move that one to the bottom of the pecking order. This makes our global RRM less disruptive than any legacy implementation.
Using DFS as an example clients. Don’t respond well to DFS hits.
They might not scan certain channels, and they might make poor AP choices. In our implementation, we reorder the channels in a pecking order, based on what we’ve seen in that environment over time.
So certain channels are automatically prioritized.
So you might see channels that appear to be a good choice, based on current channel and spectrum utilization. But we know there exists a high degree of risk of DFS hits, based on what we’ve learned over time, so these channels are prioritized. This is truly a self-driving system, and it’s not solely focused on channel reuse.
Stepping back, legacy RRM system lacked the tools to measure if things actually got better for your users. With Mist, the Capacity SLE is exactly that measurement that you’ve never had. If theCapacity SLE takes a hit, and it’s due to Wi-Fi or non-Wi-Fi interference, and RRM is not able to make any changes, then you obviously know there’s something in your environment you need to take a look at.
Or if RRM is making changes and things are not getting better, then you have some other issue that needs to be addressed. But at least you know, being able to quantify the system is getting better is super important, especially once you start deploying a lot more devices. Today’s requirements may not warrant this level of sophistication, but once you start throwing a lot of IOT devices, and other unsophisticated RF devices on the network, our system will learn to accommodate them.
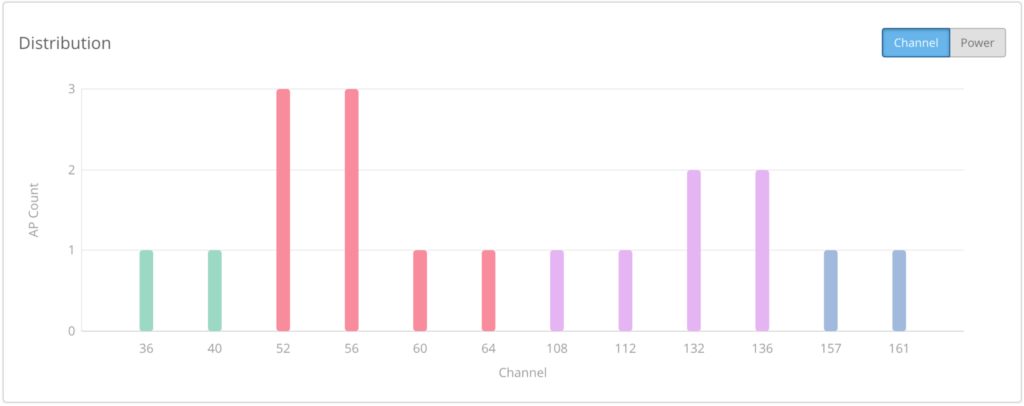
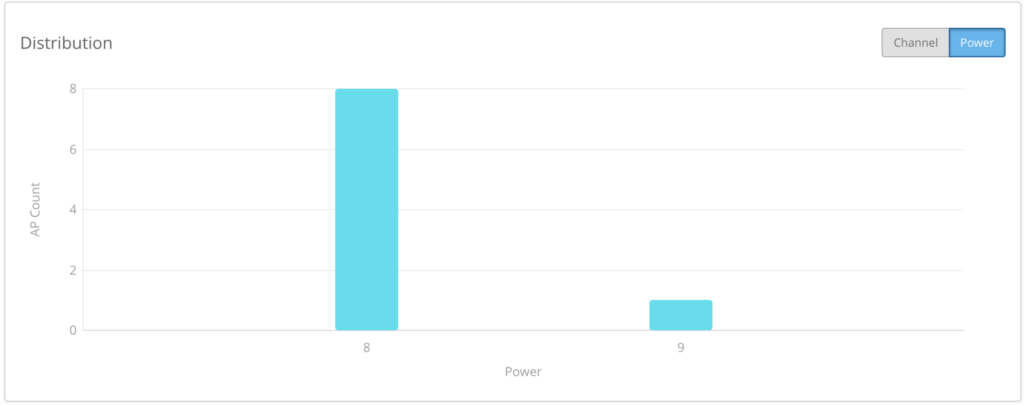
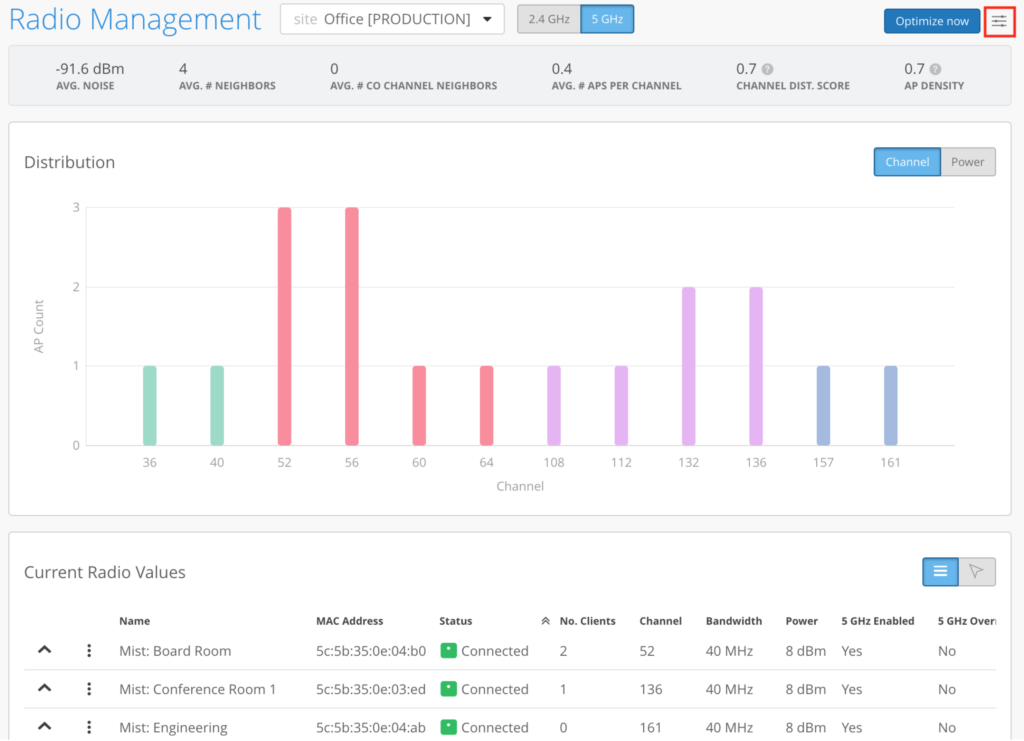
To see the channel distribution, you can take a look at this graph.
This is from our office, and it’s not the perfect RF environment.
This graph shows you what the channel distribution looks like. But when you have hundreds of thousands of apps and thousands of sites, you need automations that baseline and monitor, using metrics that you trust. What we’ve done is added this top level metric into RRM. So instead of pulling all of your APs and manually inspecting channel assignments, you can simply use our API to pull a single metric.
We have a distribution and a density score.
We have an average co-channel neighbors, average number of neighbors. So if you have a standard deployment policy which an installer did not follow, you will see the site isn’t in compliance, based on these values immediately. You can pull this from the API and create a post-deployment report.
So if any of these metrics are deviating, you will know exactly where to focus. These SLEs and metrics are available on an ongoing basis.
Compare this with existing vendors, where you would have to pull raw metrics and create your own formula to see if you need to take any actions.
We don’t want you to pull raw data, we just want you to use site level metrics.
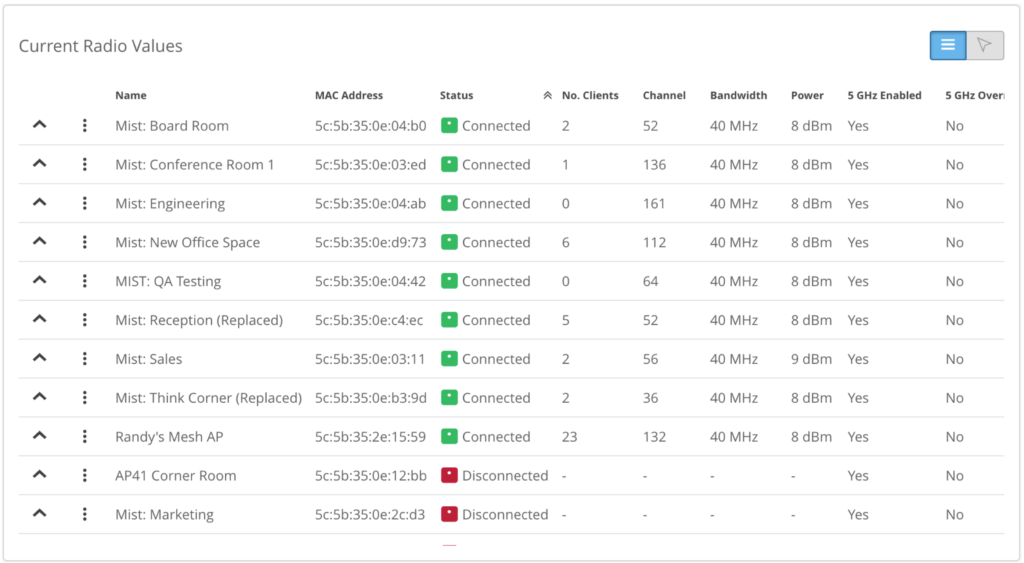
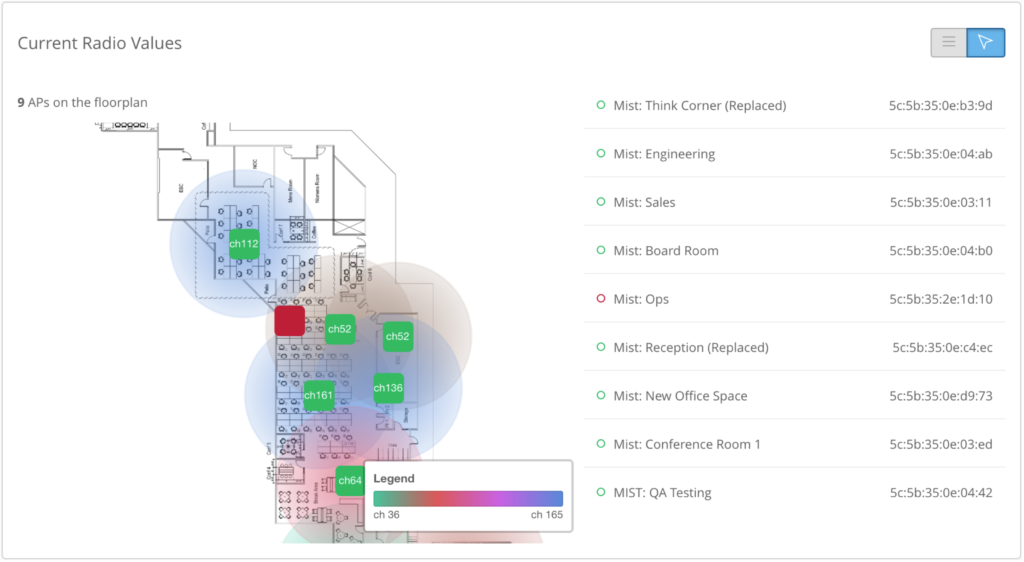
But if you want to maintain your own reports, where you already have done the dedupe and aggregation for you from a deep troubleshooting perspective, why is this AP on a particular channel, is a common question asked when chasing an issue that you suspect to be due to Wi-Fi interference. Each mist AP has a dedicated radio that scans all the channels all the time, and continually maintain a score for each of the channels that it scans.
This is the data that RRM uses to score the channel.
So whenever it gets a trigger from the capacity SLE to make a change, it uses this AP and site score to determine the channel to assign.
If an AP is on a channel that doesn’t seem optimal, you can look right here, and then at the capacity SLE to see if the decision-making makes sense.
If the SLE doesn’t show a user hit, that explains why the AP hasn’t changed channel yet. It will defer to the global plan and make the change at night.
If there were user impact, the system would have made a change right away.
In short, we have a self-driving, reinforcement, learning-based RRM implementation. At the same time, we’re also providing you with the visibility into the decision-making process so you can validate decisions made by them.
You also have the ability to pull information at scale via our APIs, and maintain a baseline and trend data for all your sites. This is valuable if you’re asked to deploy a bunch of new devices, and the question comes up, hey, do we have the capacity to support this?
With a baseline and trend information. You can make informed decisions without having to pull all kinds of raw data and make a guess. Typically, you want to make adjustments in two to three DBM increments, so you have enough wiggle room. Unlike Cisco Meraki, we will go up and down in increments of one, so there’s more granularity. But as best practices suggest, we always give it a range plus-minus 3 Dbm from a median value, typically the target used by your site survey predictive design.
We had one customer ask us why their coverage SLE was 99% when they had excellent coverage in their warehouse, which was full of Wi-Fi-driven robots. In the past when there was a robot problem, the client team would inevitably blame the infrastructure team. The infrastructure team would request detailed logs from the client team, and most of the time that led to no actions.
When Mist was installed, and we saw the 99% coverage SLE, we looked at the affected clients, and it always seemed to be the same robot. When they asked the client team about it, they said, yeah, that robot has always been a little quirky. So when they took the robot apart, they found a damaged antenna cable. This was eye opening to this customer, and their quote to us was, you guys solved the needle in the haystack problem.
Coverage SLE is a powerful tool. In another customer, a driver update was pushed to some of their older laptops.
They have over 100,000 employees. So they did do a slow rollout, but they started getting Wi-Fi complaints almost right away.
Their laptops are configured with 5-Gig and 2.4-Gig profiles already installed, because each of their sites are a little different in their capabilities.
What happened in this update, it caused laptops to choose 2.4, when they normally would have chosen 5 gig. So the SLEs immediately showed a significant deviation from baseline that correlated to those specific device types and the sites that were having the problem. They immediately stopped the push, because the correlation was obvious.
This customer told us that in the past they would have asked a user to reproduce the problem, so they could collect the telemetry they needed to diagnose the problem. Now they realize Mist already has the telemetry needed to tell them they have a growing problem and what that problem was, and save them a ton of time. That is the power of Mist AI RRM.